Passing the AWS Certified Machine Learning Engineer Associate Certification in 2025

The AWS Certified Machine Learning Engineer — Associate certification will help validate technical ability in implementing ML workloads in production and operationalizing them. Boost your career profile and credibility, and position yourself for in-demand machine learning job roles.
As stated in the AWS Certified Machine Learning Engineer — Associate (MLA-C01)Exam Guide, this certification covers the following topics:
- Ingest, transform, validate, and prepare data for ML modeling.
- Select general modeling approaches, train models, tune hyperparameters, analyze model performance, and manage model versions.
- Choose deployment infrastructure and endpoints, provision compute resources, and configure auto scaling based on requirements.
- Set up continuous integration and continuous delivery (CI/CD) pipelines to automate orchestration of ML workflows.
- Monitor models, data, and infrastructure to detect issues.
- Secure ML systems and resources through access controls, compliance features, and best practices
Study Approach
The AWS Certified Machine Learning Engineer Associate site provides a good overview of the certification material. You can find detailed information inside the Exam Guide as well. For most certifications, I start with a video course to get started. For this certification, I would suggest you try one of the following:
- Stephane Maarek and Frank Kane’s AWS Certified Machine Learning Engineer Associate: Hands On! course (Get a coupon for Stephane Maarek’s course at Datacumulus ).
You should be able to get this course for under $20 with coupons. Once you have gone through a video course, you should have a good understanding of the overall material and have a basic understanding of what is required.
Practice Questions
Now, getting ready for any certification involves some form of practice question training. I try to get the best set of questions based on recent reviews and prefer to have multiple question sets to train on.
I used the following AI Practitioner Practice tests
- Tutorials Dojo AWS Certified Machine Learning Engineer Associate Practice Exams(183 Questions, 2 65 question Full Tests and 53 additional questions, with randomized full tests)
- Whizlabs AWS Certified Machine Learning Engineer Associate Practice Tests (109 questions, a full test and 44 additional questions)
- ExamTopics Amazon AWS Certified Machine Learning Engineer — Associate MLA-C01 Exam(20 free questions, 85 overall)
- AWS Certified Machine Learning Engineer — Associate(MLA-C01) (20 free questions)
Other question sets you might consider:
- AWS Machine Learning Engineer Associate Cert (Stephane Maarek & Abishek Singh) (2 Practice Tests (35 & 65 questions, unsure if there is overlap between them) (Check https://datacumulus.com/ for coupon)
- Practice Exams | AWS Machine Learning Engineer — Associate by Nikolai Schuler (Looks like 4 x 65 questions)
Practice Test Training
Now preparing for the examination involves doing plenty of training on the practice tests above. This will help you identify your areas of weakness and areas you need to dive into a bit more. Using multiple question materials will benefit you as they are all a bit different and emphasize different areas.
There are 3 main sets of questions I used and I will discuss them below. Generally, I like to get to a point where I would get a 100% on exams just to be sure I had a good handle on the testing material. The testing material is not always the same as the actual exam but maximizing your mastery of the testing material should help with the real exam.
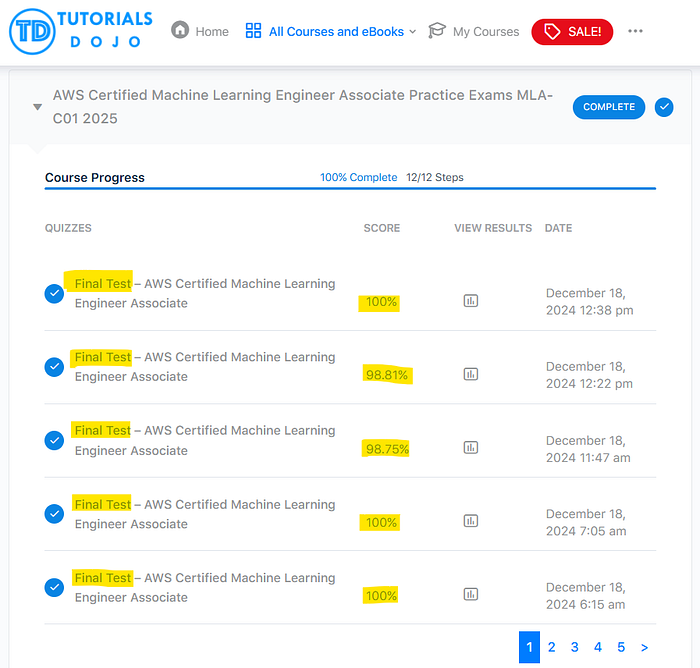
Tutorials Dojo offers good questions to practice on and you can review your incorrect responses to get a better grasp of the material. There are different modes as well such as Timed Mode and Review Mode to change things up a bit. The final mode is the “Final Test” which offers a randomized set of 65 questions.
You will start out completing the tests taking a fair amount of time and with less than desired marks. If you keep practicing you should see improvement to high marks and the testing time will come down drastically.
When I can get a 100% on a fully randomized test and average near that I generally feel ready to take the real test. Coincidentally, this is also the point where I am also getting really tired of studying as well.
Good set of questions that are really indicative of the actual exam questions. There is a bunch of annoying CAPTCHA and password items when using the free version which is understandable.
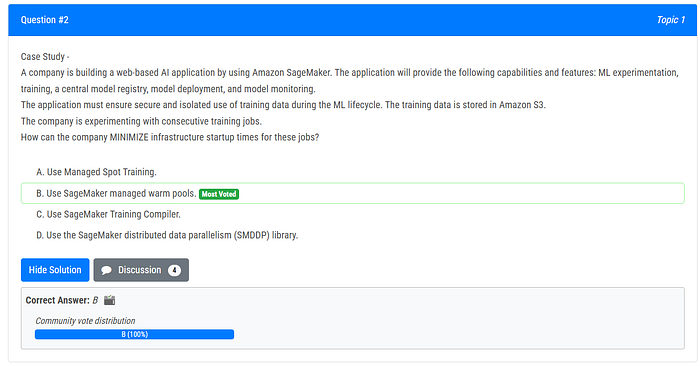
You have to discern between the “Most Voted” answer and the initial answer that ExamTopics presents. Generally, I would go with the answer that was selected based on the Community vote distribution after reading the comments. There is a Discussion popup and it will show you other viewers comments and generally the “Most Voted” response is the one you should really consider in my opinion. You can also open up the Discussion to see the arguments for the different choices.
Exam Topics does not actually provide 65 question sets and mark them. There currently are not a lot of questions there but they are very realistic.
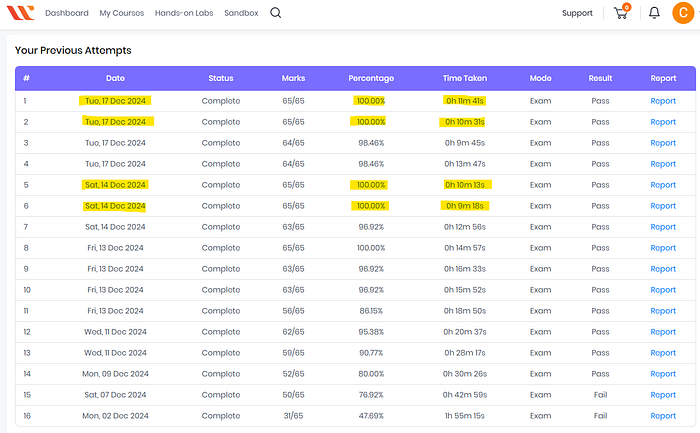
Whizlabs offers additional questions at a reasonable price. Questions are not randomized for most of the questions. This tends to lead you to actually start to remember the right responses based on memory.
Personal Tips on questions
Be consistent in taking your tests to get more comfortable with the material. Try to figure out what is the best time of day for you to practice and try to set up a schedule to practice.
Also, don’t be afraid to get poor marks at the start. View that as an opportunity to improve and each time you take a new test after reviewing the incorrect responses from last time. You will quickly notice that your scores will get better and the time to complete a test will come down as well.
Key points
One-hot encoding — conversion of categorical information into a format that may be fed into machine learning algorithms to improve prediction accuracy.
Feature Splitting — dividing single features into multiple sub-features or groups based on specific criteria.
Logarithmic Transformation — the process of taking a mathematical function and applying it to the data.
LightGBM — is a popular and efficient open-source implementation of the Gradient Boosting Decision Tree (GBDT) algorithm. GBDT is a supervised learning algorithm that attempts to accurately predict a target variable by combining an ensemble of estimates from a set of simpler and weaker models
Mean absolute error(MAE) — measure of errors between paired observations expressing the same phenomenon. Examples of Y versus X include comparisons of predicted versus observed
AWS Glue Databrew — visual data preparation tool that enables users to clean and normalize data without writing any code.
AWS Glue Data Crawler — populates the AWS Glue Data Catalog with databases and tables
AWS Glue FindMatches —
Residual Plot — Visualize performance. observation in the evaluation data is the difference between the true target and the predicted target
Scatter Plot — can highlight general trends but do not provide insight into whether the model is systematically underestimating or overestimating values
Accuracy — refers to the percentage of correct predictions.
Receiver Operating Characteristic (ROC) curve — industry-standard accuracy metric for binary classification models
Precision — reducing false positives
f1 — combines precision and recall into a single metric by computing their harmonic mean, making it a good choice when dealing with imbalanced datasets.
Principal Component Analysis (PCA) — Algorithm is an unsupervised machine learning algorithm that attempts to reduce the dimensionality
Temperature — Affects the shape of the probability distribution for the predicted output and influences the likelihood of the model selecting lower-probability outputs.
- Choose a lower value to influence the model to select higher-probability outputs.
- Choose a higher value to influence the model to select lower-probability outputs.
Top K — This parameter limits the model from considering only the top K, most likely the next tokens at each step of generation. A lower Top K value makes the output more focused and predictable.
Top P (nucleus sampling) — This parameter sets a cumulative probability cutoff for token selection. The model only considers the most likely tokens whose cumulative probability exceeds the Top P value. A lower Top P makes the output more focused and deterministic.
TensorFlow and PyTorch, — ideal for defining and training convolutional neural networks (CNNs) for image classification task
SHAP baseline — Explanations are typically contrastive, that is, they account for deviations from a baseline.
Residual Plot — residual plot is a visual tool often used in regression analysis to evaluate how well a predictive model performs by comparing the differences (residuals) between actual and predicted values
Logistic regression is a machine learning technique that predicts outcomes by analyzing historical data
Amazon SageMaker with TensorBoard is a feature of Amazon SageMaker that integrates the visualization tools of TensorBoard
Amazon SageMaker Sequence to Sequence is a supervised learning algorithm where the input is a sequence of tokens (for example, text, audio),
Amazon SageMaker’s Automatic model tuning (AMT), also known as hyperparameter tuning, finds the best version of a model by running many jobs that test a range of
Spearman — particularly useful when analyzing relationships between numeric features where the relationship might not be linear or when the data does not meet the assumptions of normality.
Difference in Proportions of Labels (DPL) — evaluates skewness in favorable results. Measures the imbalance(skewness) of positive outcomes between different facet values.
Kullback-Leibler Divergence (KL) — Measures how much the outcome distributions of different facets diverge from each other entropically. assesses entropy-driven disparity
Total Variation Distance(TVD) —Measures half of the L1-norm difference between distinct demographic distributions of the outcomes associated with different facets in a dataset.
Conditional Demographic Disparity(CDD) — Measures the disparity of outcomes between different facets as a whole, but also by subgroups.
Target Tracking scaling policies — automatically scales the capacity of your Auto Scaling group based on a target metric value.
Shapley values — help you understand what impact your feature has on what your model predicts
Quantization — effectively reduces the memory usage and computational demands of neural networks
Inference Recommender — reduces the time required to get machine learning (ML) models in production by automating load testing and model tuning across SageMaker AI ML instances
Pipe Mode — streams data directly from an Amazon S3 data source
NetApp SnapMirror — replicates data between two different ONTAP systems using proven replication technology
Kendra — a managed information retrieval and intelligent search service that uses natural language processing and advanced deep learning model
Latent Dirichlet Allocation (LDA) algorithm — primarily used to identify a specified number of topics within a set of text documents. In this context, each document is considered an observation
Higher Temperature — to select lower-probability outputs (More creative)
Higher Top P — to allow the model to consider less likely outputs.
Additional Topics
These are some topics or thoughts that I did not see in the training materials that you might want to consider as well. My thoughts are posted on this but you can take as you see fit.
- If you have a machine learning workload that is interruptible what is the right configuration of the primary, core and task nodes to be most reliable and cost effective?
You should select Primary and Core nodes to be on-demand and the Task nodes can be Spot instances. See Node Types.
2. When implementing dealing with a workload that must deal with privacy related workloads which of the following is the best to be most operationally efficient?
You will be presented with a variety of options and will come down to 2 choices. Macie and Lambda(to rectify the issue) or Comprehend and EC2 instances(to rectify the issue). I feel that Macie and Lambda could be the better choices as EC2 is not as operationally efficient. Possibly consider Use Amazon Macie for automatic, continual, and cost-effective discovery of sensitive data in S3
3. What is the best way to import a Sagemaker model import within the same region and and its model weights as well.
Consider Import custom models in Amazon Bedrock (preview) , You can select Imported Models from the Foundation models section and you can import model weights from an Amazon S3 bucket.
4. What is a way to most easily stop a model from referring to a competitor’s name if you wish to not have this happen?
Consider using Amazon Q BlockedPhrases .
5. What is the best way to deploy a shadow endpoint with the production sharing the same endpoint and they require different autoscaling requirements?
Deploy on the same Multi-Model Endpoint with different autoscaling configurations for the shadow, production or other endpoints. See Set Auto Scaling Policies for Multi-Model Endpoint Deployments
6. Know the advantages, disadvantages of when to use either blue-green or in-place deployments.
Review Working with deployments in CodeDeploy. In-place takes less resource utilization is one reason.
7. If you are generating audio from text and you need to add pauses, what is the best approach?
You can used Polly with SSML Tags. See Supported SSML tags .
8. What is the best way to manage API Keys with KMS, Secrets Manager and Parameter Store?
One might consider Secrets Manager for this based on What is AWS Secrets Manager?
9. If you are managing an a marketing application that is going to provide different colors which will require a number of unique values in a selected categorical variable. Should you use One Hot Encoding or Label encoding.
I might venture that One Hot Encoding is preferred. See ONE_HOT_ENCODING .
10. If you are needing a visualization of data manipulation with Data Wrangler, what is the easiest way to handle visualizations?
Amazon SageMaker Data Wrangler includes build-in analyses that help you generate visualizations and data analyses in a few clicks. See Analyze and Visualize . Quicksight is a possiblity but probably not required as Data Wrangler handles this already.
11. Read up on Managing FSx for ONTAP volumes.
Conclusion
You will learn a lot about implementing ML workloads in production and operationalizing them by studying for this certification. Use this as an opportunity to learn more. Use a video course and practice often to prepare sufficiently before taking the test.
Best of luck on your preparation and hopefully this article helps you to pass the AWS Certified Machine Learning Engineer — Associate certification
Best of luck!

