Passing the AWS Certified Machine Learning — Specialty Certification in 2025

The AWS Certified Machine Learning Specialty exam is a challenging AWS Certification. This examination covers topics related to Machine Learning within the AWS Environment.
As stated in the AWS Certified Machine Learning — Specialty (MLS-C01) Exam Guide covers the following domains:
- Domain 1: Data Engineering (20% of scored content)
- Domain 2: Exploratory Data Analysis (24% of scored content)
- Domain 3: Modeling (36% of scored content)
- Domain 4: Machine Learning Implementation and Operations (20% of scored content)
Study approach
You can learn more about this certification on the AWS Website . Specifically you can review the Exam Guide for details to be covered. The approach that I generally use is to get a video course of your choosing that will give you an overview of the material. I used Frank Kane/Stephane Maarek Udemy Course to prime myself for the material. You can get coupons for this Udemy course at https://www.datacumulus.com/ website or wait for Udemy sales. Generally, the price should always be less than $30. Go through the course to get an overview material to be covered. Once you have completed this, you should move on to training on practice questions.
This is a good and engaging course to move you through the material to pass the exam.
Practice Questions
Preparing for the exam experience will involve on practicing on question sets to ensure that you can get the right level of comfort with the material before you write the actual exam. I used the following question sets:
- Tutorials Dojo Machine Learning Specialty Practice Exams (158 Questions)
- ExamTopics Practice Questions (140 Free Questions, 296 questions with subscription)
- Whizlabs Machine Learning Specialty Questions(245 questions total, 3 65 question sets and 5 section tests of 10 questions each)
- AWS Sample Questions (10 questions) (Printed these ones out on paper and ran through them while watching tv)
Another question set included that I did not use but you could investigate:
- AWS Certified Machine Learning Specialty (2 x 65 questions)
General training approach
- Be consistent about your effort by trying to practice daily if you can
- Approach incorrect responses as an opportunity to learn more (Don’t get dejected over incorrect answers when training)
Practice test training
It is really important to practice with some testing materials to help you get familiar with what to expect on the exam. You will quickly understand your areas of weakness as well. I also think that using multiple question sources will help make you more well rounded.
There are 3 main sets of questions I used and I will discuss them below. Generally, I wanted to get to a point where I would get a 100% on exams just to be sure I had a good handle on the testing material. The testing material is not always the same as the actual exam but maximizing your mastery of the testing material should help with the real exam.
Tutorials Dojo offers good questions where you can practice and save your results to review afterwards. You can work through the different Timed Mode and Review Mode questions until you get comfortable to do the “Final Test” which is a randomized set of 65 questions.
You will start out completing the tests taking a fair amount of time and with less than desired marks. If you keep practicing you should see improvement to high marks and the testing time will come down drastically.
I was getting essentially 100% and completing the 65 set questions in 11–13 minutes at the end when I decided I was ready to attempt the real exam.
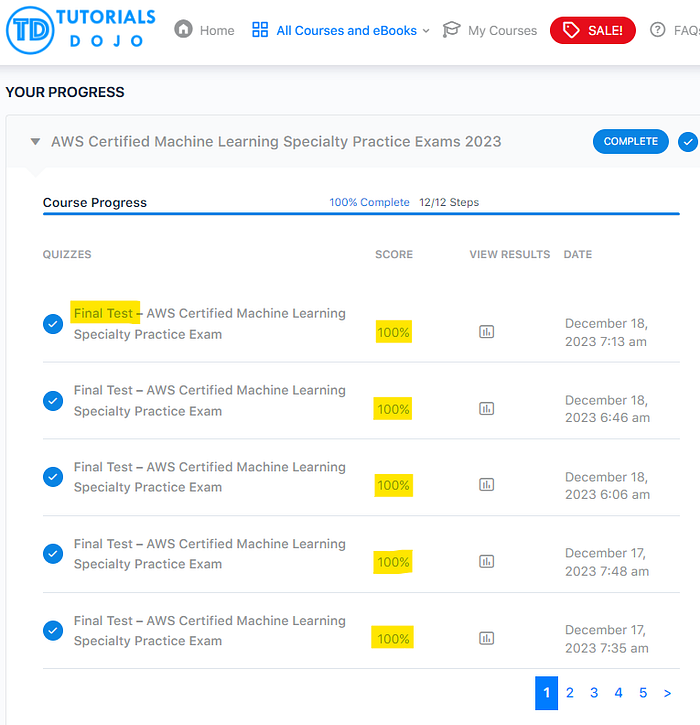
Good set of questions that are really indicative of the actual exam questions. There is a bunch of annoying CAPTCHA and password items when using the free version which is understandable.
You have to discern between the “Most Voted” answer and the initial answer that ExamTopics presents. Generally, I would go with the answer that was selected based on the Community vote distribution after reading the comments. There is a Discussion popup and it will show you other viewers comments and generally the “Most Voted” response is the one you should really consider in my opinion. You can also open up the Discussion to see the arguments for the different choices.
Exam Topics does not actually provide 65 question sets and mark them. I generally did 25 question sets to get through all of the questions.
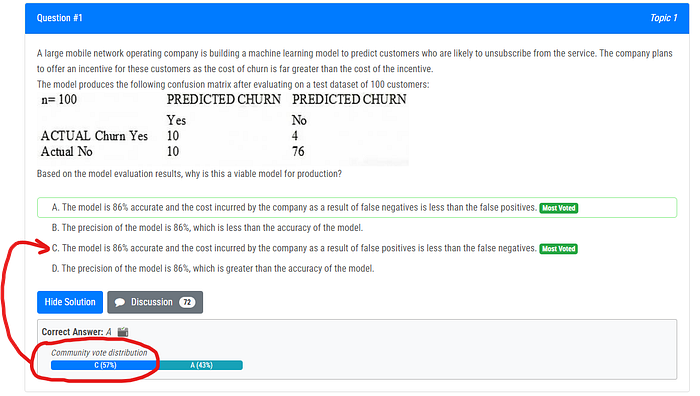
They seem to include some questions that don’t seem to directly apply to the actual certification questions. (Extra information about the topic in general which proves that it was written by someone who is an expert in the field but also information that does not necessarily apply to the exam itself)
Questions are not randomized for most of the questions, but there is a “Final Test” which is randomized with respect to the overall questions included but not the responses themselves. This tends to lead you to actually start to remember the right responses based on memory.
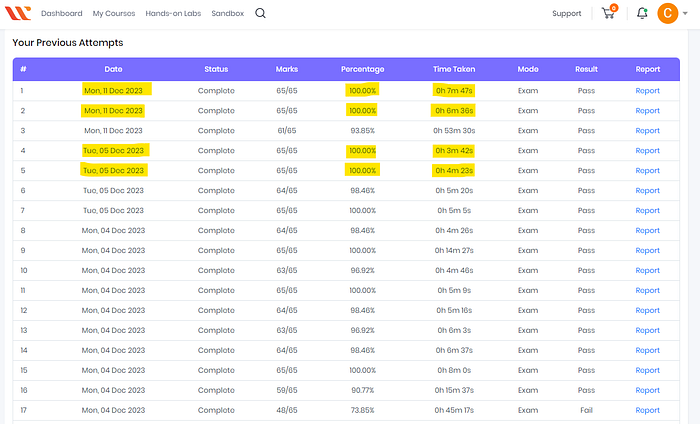
Whizlabs does offer plenty of questions to create value although the questions.
Personal Tips on questions
Be consistent in taking your tests to get more comfortable with the material. Try to figure out what is the best time of day for you to practice and try to set up a schedule to practice.
Also, don’t be afraid to get poor marks at the start. View that as an opportunity to improve and each time you take a new test after reviewing the incorrect responses from last time. You will quickly notice that your scores will get better and the time to complete a test will come down as well.
Key points
The following are some key points to remember/understand when studying for this exam:
Concepts:
Amazon Augmented AI —allows you to conduct a human review of machine learning (ML) systems to guarantee precision.
Bag of words — a model of text which uses a representation of text that is based on an unordered collection (or “bag”) of words
AWS Data Wrangler — reduces the time it takes to aggregate and prepare tabular and image data for ML from weeks to minutes
Elastic inference — allows you to attach low-cost GPU-powered acceleration to Amazon EC2 and Sagemaker instances to reduce the cost of running deep learning inference
Ground Truth — most comprehensive set of human-in-the-loop capabilities, allowing you to harness the power of human feedback across the ML lifecycle to improve the accuracy and relevancy of models
Horovod distributed framework — provide distributed training support to Apache MXNet, PyTorch, and TensorFlow.
Inference Pipeline — is composed of a linear sequence of two to fifteen containers that process requests for inferences on data (Real-time predictions)
Multiple Imputations by Chained Equations(MICE) — a principled method of dealing with missing data
N-gram — contiguous sequences of n items from a given sample of text or speech
Pipe Mode and Protobuf RecordIO format — Speed up the training process
Regularization/Normalization — Normalization usually scales data back to [0,1](usually less drastic than regularization), Regularization adjusts the prediction function (helping with exponential/logarithmic transforms)
Residual plots — represent the portion of the target that the model is unable to predict
Redshift ML — makes it easy for data analysts and database developers to create, train, and apply machine learning models using familiar SQL commands in Amazon Redshift data warehouse
SageMaker Neo — optimize machine learning (ML) models for inference on SageMaker in the cloud and supported devices at the edge
Synthetic Minority Oversampling Technique (SMOTE) — where synthetic minority samples are created by interpolating pairs of the original minority points
Models:
Bayesian Search — Bayesian Search requires less training jobs
Collaborative Filtering — recommends products based on historical user-product interactions.
DeepAR — a supervised learning algorithm for forecasting scalar (one-dimensional) time series using recurrent neural networks (RNN)
Factorization Machines — general-purpose supervised learning algorithm that you can use for both classification and regression tasks. good choice for tasks dealing with high dimensional sparse datasets, such as click prediction and item recommendation.
KNN — the algorithm queries the k points that are closest to the sample point and returns the most frequently
K-means — an unsupervised learning algorithm that can be used to segment the population into different groups
Latent Dirichlet Allocation (LDA) Algorithm — attempts to describe a set of observations as a mixture of distinct categories/topics
Principal Component Analysis(PCA) — reduces the dimensionality of the model with feature reduction
Random Cut Forest — unsupervised algorithm for detecting anomalous data points within a data set
Semantic Segregation — a fine-grained, pixel-level approach to developing computer vision applications. (ie. Identify the shape of a a person in real-time)
Sequence-to-sequence (Seq2seq) — input is a sequence of tokens (for example, text, audio), and the output generated is another sequence of tokens
t-Distributed Stochastic Neighbor Embedding (TSNE) — is a non-linear dimensionality reduction algorithm used for exploring high-dimensional data
Terms Frequency-Inverse Document Frequency(TF-IDF) — measures how important a term is within a document relative to a collection of documents
TensorFlow — is an open-source machine learning (ML) library widely used to develop heavy-weight deep neural networks (DNNs) that require distributed training using multiple GPUs across multiple hosts.
Quantile Binning — create uniform bins of transformations (classifications)
Word2Vec — maps words to high-quality distributed vectors
XGBoost — a supervised learning algorithm that attempts to accurately predict a target variable by combining an ensemble of estimates from a set of simpler and weaker models
Curves:
AUC (Area Under the Curve) — measures the ability of a binary ML model to predict a higher score for positive examples as compared to negative examples.
ROC Curve (Receiver Operating Characteristic Curve) — measures the ability of the model to predict a higher score for positive examples as compared to negative examples.
PR Curve — represents the tradeoff between precision and recall for binary classification problems. (best to evaluate models in which most of the cases are negative)
F1 — the harmonic mean of the precision and recall, defined as follows: F1 = 2 * (precision * recall) / (precision + recall)
MAE(Mean absolute error) — measure of how different the predicted and actual values are, when they’re averaged over all values
MSE(Mean Squared Error) — average of the squared differences between the predicted and actual values
Precision — measures how well an algorithm predicts the true positives (TP) out of all of the positives that it identifies. Precision = TP/(TP+FP)
Recall — measures how well an algorithm correctly predicts all of the true positives (TP) in a dataset. Recall = TP/(TP+FN) (No false positives)
Softmax Function — notion of confidence about whether or not a predicted class
Tips when looking at questions:
- Least effort/Least configuration/Most efficient approach with respect to transformation of data is almost always AWS Glue
- Cost effective ingestion is almost always AWS Kinesis Firehose
- SageMaker batch transform is the best way to deal with huge data sets
- Random Cut Forest function is for all anomaly detection
- Overfitting is dealt with by increasing the dropout hyperparameter
- Residuals (Residual plots) are useful for evaluating(if underestimating or overestimating) a target
- AWS Batch will quicken up times
- If you are dealing with 150TB(or so)of predictions, EMR is likely required
- Naive Bayesian assumes features are conditionally independent, Full Bayesian assumes them to be statistically dependent
- When model accuracy decreases when deployed to production, you should acquire/generate more training data
- Add features if you are underfitting in training environment
- Regularization/increase data if it does well in training but not in production
- Real-time is always Kinesis Data Streams rather than Kinesis Data Firehose or Glue
- DeepAR should be selected for any time-series datasets
Model Performance Issues
Smaller number of spam emails — Adjust Score Threshold
Generalized poorly in production — Increase applied regularization
Dealing with Overfitting & Underfitting:
Underfitting: Add Features/Decrease amount of regularization
Overfitting*: Reduce features/ Increase Regularization
Overfitting implies it does well in training but not in production
Distractor words
The following words are possible examples of distractors or responses that generally should not be selected as a rule:
- Mechanical Turk is never to be selected
- BlazingText is never to be selected
- Anything with Marketplace is likely a distractor as well
- Anything with Apache, OCR or other non-AWS technologies
Additional information to consider/review when studying
These are some items you might want to consider as they were not really covered in the testing materials I looked at. This is likely due to the fact that this exam was first put on October 21, 2019 and hasn’t had a major update since then. I think the training providers could enhance their materials by including some of the following:
AWS Sagemaker Clarify — provides purpose-built tools to gain greater insights into your ML models and data, based on metrics such as accuracy, robustness, toxicity, and bias to improve model quality and support responsible AI initiative
Use of Textract to detect signatures — within documents by using the AnalyzeDocument API
AWS Fraud Detector — to easily build, deploy, and manage fraud detection models without previous machine learning (ML) experience
AWS Model Monitor — monitors the quality of Amazon SageMaker machine learning models in production. Monitors data quality, model quality, bias drift and Feature Attribution Drift. It felt like the old exam material spoke of CloudWatch but I feel that Model Monitor is filling that functionality moving forwards.
CreatePresignedDomainUrl — to create a URL for a specified UserProfile in a domain. A presigned URL is created.
Use of target_precision and target_recall — target_precision maximizes precision and target_recall maximizes recall
The write_time attribute -used to sort Athena query results to get the latest results
The use of a training.parquet and testing.parquet files to speed up training of models.
Latent Dirichlet Allocation (LDA) Algorithm — to use find categories / groups
Conclusion
You will learn a lot working through this certification. Start with a video course, followed by good practice questions to improve your knowledge and also quicken how fast you can respond.
Best of Luck!
