Single Table Design with AWS DynamoDB and the Inverted Index

Overview
Many people love the concept of DynamoDB as a serverless option to storing data. However, often people associate DynamoDB as only a Key Value store. This is where the single table design steps in and can make this happen. The single table design was created by Rick Houlihan and popularized by Alex DeBrie .
Many people are all to familiar with Relational Databases and the normalization process. The concept of having a serverless and highly scalable performance database is great but this requires a different approach to development. With relational databases the process involves creating tables and linking them with primary keys and foreign keys. If you need a new entity, you simply create a new table and then have it linked via primary keys and foreign keys.
Rather than relational database keys, DynamoDB utilizes indexes to make it possible to efficiently access data within DynamoDB tables. These include Primary Keys (Partition key and sort key), Global Secondary Indexes(GSI) (Partition Key and Sort Key), and Local Secondary Indexes(which provide additional sort keys) I invite the reader to explore more on a DynamoDB Introduction.
AWS defines 9 Steps in the DynamoDB Data modelling process steps as but we will focus on:
- Identify your data access patterns
- Create the DynamoDB Data model
- Validate the data model
It is easy to get lost in the DynamoDB concepts and even some of the examples that you can read. This article will hope to offer a simple example which actually links to some actual code to make it more real.
We have created a sample application called Santa’s Workshop which is a working model with a use case to help out Santa Claus. He receives many letters and each letter can have request multiple toys. This cannot be represented in a key store database because you need to implement a relationship between the letters and the toys.
A key benefit of the single table design is to implement many to many relationships in both directions. Most are familiar with a relational database model but the single table design makes this possible for DynamoDB.

Identify the Data Access Patterns
For Santa’s Workshop, we want to represent the letters sent from children which contain a list of toys and the quantity they wish to receive for each toy. The 2 main entities are Letters and Toys to model in this scenario
Letters in this model should contain an id, a total price(sum of net cost of all toys included), and address, date received and an address.
Toys in this model should contain an id, name, description and price.
For the single table design we will call our DynamoDB table Letters and this table will contain the entities Letters and Toys.
Data Access Patterns for this DynamoDB table are:
- Get full list of toys with their attributes
- Get individual toy with their attributes
- Get full list of letters with their attributes(including list of toys along with their attributes
- Get individual letter with its attributes(including list of toys)
- Create a new letter
- Create a new toy
- For a given toy, retrieve a list of all letters requesting that toy and the total number of Toys that Santa must deliver
- For a given letter, retrieve the letter information and information on the toy prices
- We need to retrieve the letter history information which is a snapshot of the letter information and the toy prices at the time that the letter was received and this should be in JSON format
Creating the DynamoDB Data Model
Now that we have the access patterns and the list of attributes we can start to model what this database could look like. Often you can do this in a spreadsheet or even the NoSQL WorkBench
DynamoDB does not have to be as concerned with data normalization and some data may be duplicated.
We can end up with something that looks like this:
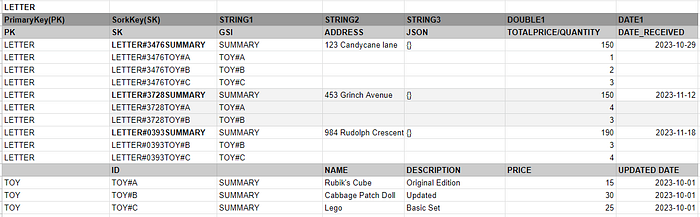
Letters and Toys are divided by populating the unique primary key field with LETTER or TOY. This allows one to query for these specific entities.
When looking at most of the DynamoDB single table designs available on the internet, they are based on a single unique value in the PK field(such as USER#ALEXDEBRIE or RACER-1) which does not lend itself to retrieving a set of objects(like Letters or Toys in this case). So this is dealt with by having the PK field store the entity category (LETTER/TOY) and the SK field will store the unique identifier of the actual object and what type of row the entity actually is(a summary row or a toy detail row in the case of the letter entity).
LETTER has been implemented with a SUMMARY row to store information on the LETTER overall such as the address, letter history information, total letter price(cost) and the date the letter was received.
LETTER has been implemented with individual TOY rows to store which toy was demanded along with the quantity of each toy for this letter.
TOY is more simple that the LETTER as it only requires one row holding attribute information.
A consideration for this structure also included the fact that you cannot use the BEGINS_WITH function on the Primary Key of the DynamoDB table. As we need to query all for all of the Letters and Toys without scans that we store LETTER and TOY in the PK field. This actually prevents you from creating entries such as LETTER#… or TOY#… in the PK field. So when looking up an individual letter or toy, we query based on the PK(with LETTER or TOY) and the associated SK with a BEGINSWITH(“TOY#ID”)

Now if we look at Data Access Pattern where we need to the number of toys requested for a given toy, we cannot do this with the Primary Key. This is where we will utilize the inverted index
An inverted index is a common secondary index design pattern with DynamoDB. This involves a secondary index that is the inverse of the primary key for the DynamoDB table which allows one to query the “other” side of a many-to-many relationship which is not really possibly in a general key value store approach.
In this case, we will create a GSI on the STRING1 field of the DynamoDB table. With this GSI, we can query the DynamoDB on the STRING1 elements for all of the TOYs and we can do a lookup for all the associated LETTERs.
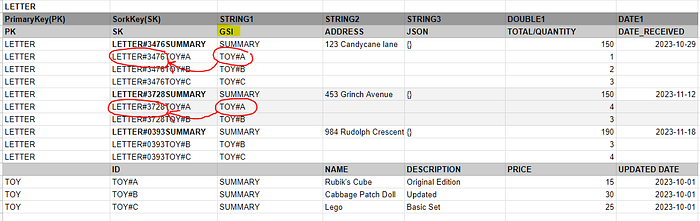
So given that we want to find all of the letters associated with Toy A, we can use the GSI Index created on STRING1 to effectively query for TOY#A in the letters. We can then just look up the individual LETTER information in the SK field.
This is how we can get this information effectively without using full scans of the data. Remember that indexes allow you to keep costs down by meeting the data access patterns and minimizing the data calls. DynamoDB is serverless which means that you pay for what you use. That is why Data Access patterns are much more important consideration for this approach. With relational databases, you simply create tables and link them with keys but with NoSQL Single Table Model, you need to consider things carefully.
Validating the Data model
We will validate the data model with some examples of working code from Santa’s Workshop .
Let us look at a couple of Data Access Patterns
Firstly, let us look at the Data Access Pattern 4 Get individual letter with its attributes(including list of toys)
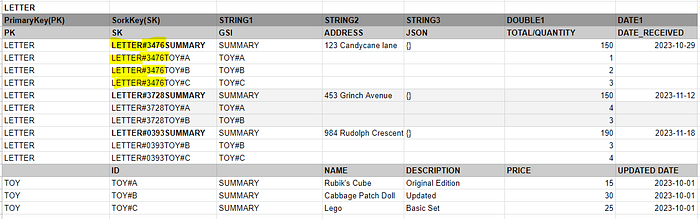
By querying the DynamoDB table based on the PK of LETTER and the SK which BEGINS_WITH LETTER#3476. This will return the 1 summary record and the 3 required TOY records which gives us the information without doing a full table scan.
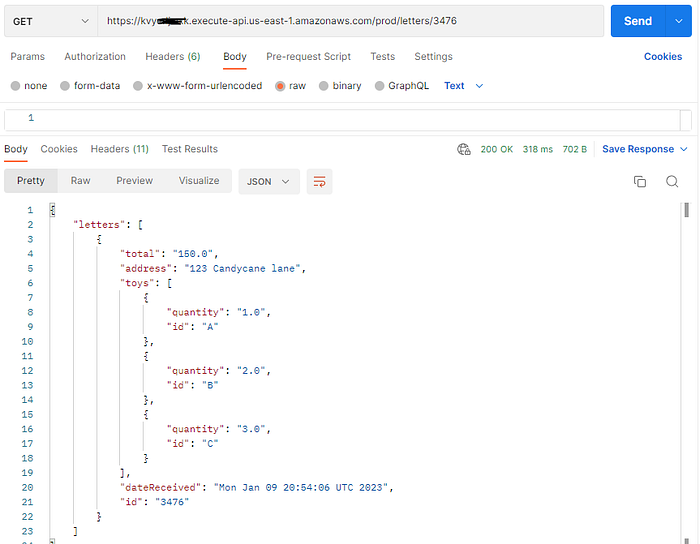
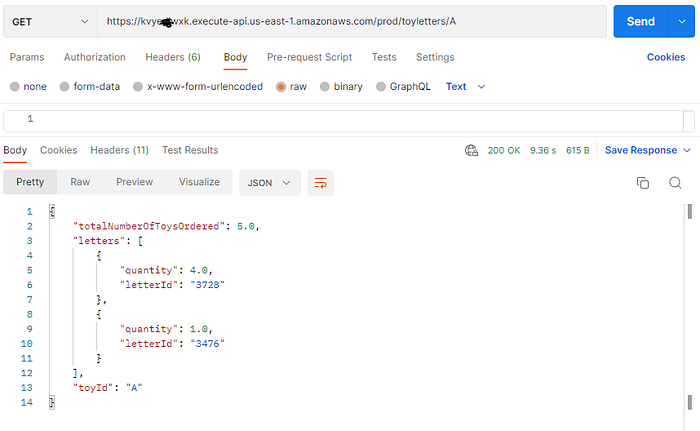
Lastly, let us look at Data Access Pattern 8 (For a given toy, retrieve a list of all letters requesting that toy and the total number of Toys that Santa must deliver)
This is achieved through the use of the Inverse Index implemented by a GSI index on the STRING1 field.
We can see that this works with the following Postman call
Feel free to explore further or look at the Santa’s Workshop further.
The important thing to understand is that if you can understand how information will be stored and retrieved with the right indexing you can develop relational modeling in DynamoDB with the Single Table Design.
Conclusion
This article demonstrates some of the key thoughts on creating a Single Table Design DynamoDB table. Each table is different with different requirements. My thoughts on this are that the key steps for this are:
- Identify the entities and attributes
- Identify the relationships between them
- Document all of the Data Access Patterns for the model
- Create a model in a spreadsheet or use NoSQL WorkBench
- Implement the model
- Test and iterate
Once you have a working model you can benefit by having a highly scalable serverless DynamoDB model. It does take some thought adjustments as this is a different process from relational database modelling.
Each Single Table design is going to be unique dependent on the entities and their attributes and relationships. There are many different approaches to meet the same requirements as well.
Additional Reading
Fundamentals of Amazon DynamoDB Single Table Design with Rick Houlihan
The What, Why, and When of Single-Table Design with DynamoDB
